CLIP Interrogator is an interesting stable diffusion demo of Text-to-image prompt inversion, i.e., output the image description text by inputting an image. It might be similar to the GAN Inversion.
In its offcial site, you will see its proud announcement: Want to figure out what a good prompt might be to create new images like an existing one? The CLIP Interrogator is here to get you answers!
The trail on this site.
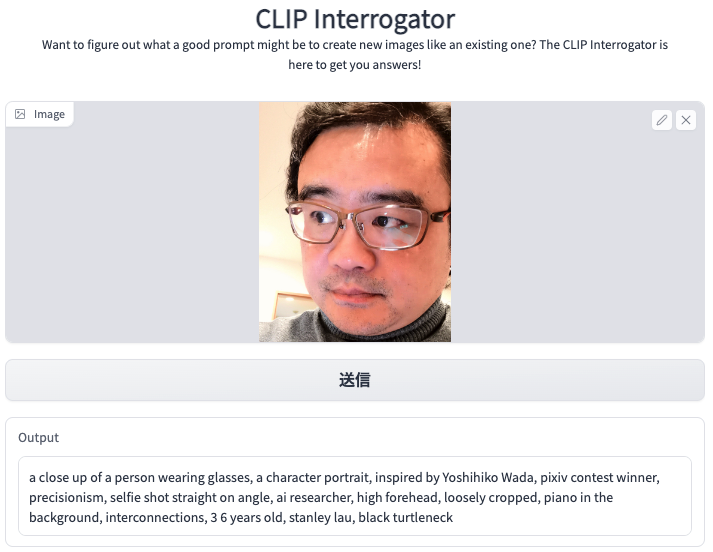
- The input is my face picture.
- After a few minutes, I got the prompt output as follows:
a close up of a person wearing glasses, a character portrait:
Right description of the picture.
inspired by Yoshihiko Wada:
*Who is Yoshihiko Wada? I searched in web and found the answer. *
pixiv contest winner:
No. Not me. But happy with the description.
precisionism:
Yes. The machine might describe it by inferring.
selfie shot straight on angle:
Yes. The machine recognizes the image correctly.
ai researcher:
Yes. The machine might describe it by inferring. Wait, wait…How does it know?
high forehead:
Yes. Inherited from my mother. Recognizes the image correctly.
loosely cropped:
Yes. Recognizes the image correctly.
piano in the background:
Yes. The machine might describe it by inferring. The same astonished! How it profiles me so profoundly.
interconnections:
Yes. By infering mechanisms. Now I feel a little terrible for this machine.
36 years old:
No. But really satisfied with the description.
stanley lau, black turtleneck.:
Yes. Excellent recognition of the image.
It’s nteresting, something like physiognomy, isn’t it?
Updated on Nov 17,2022
I did further tests on Nov 17, a few days after the above first trial on Nov 8.
(Test 1) Upload the same above picture, to confirm the same output contents if or not.
(Test 2) Upload my another picture with different hair style, clothing and face angle, to confirm the new output contents.
Result of Test 1: The output is entirely same from the first time. Now we can say its analyzing mechanisms and algorithms are stable.
Result of Test 2: The output is entirely different from the first time. However, some highly related features appear. The detailed result shows in the following screenshot.
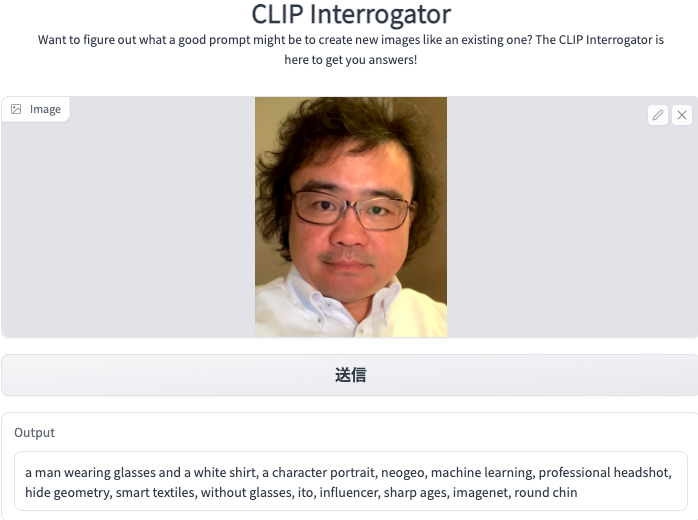
The most highly related feature is “AI researcher” from the portrait-1 output and “machine learning” from portrait-2. What an amazing machine! It knows what I am doing now. The CLIP Interrogator shows its intelligence in image-to-text analysis. Its creators are trying to develop better inference mechanisms on the recognized features from images.
Finally, I note an old Chinese saying – “相由心生,” which means “the soul surely does speak through the face to some extent.” Am I carrying a face of AI?
Updated on Nov 18,2022
Furthermore, I tested two different pictures today, named Test 3 and 4.
(Test 3)My house in Kumamoto, the countryside in Kyushu of Japan.
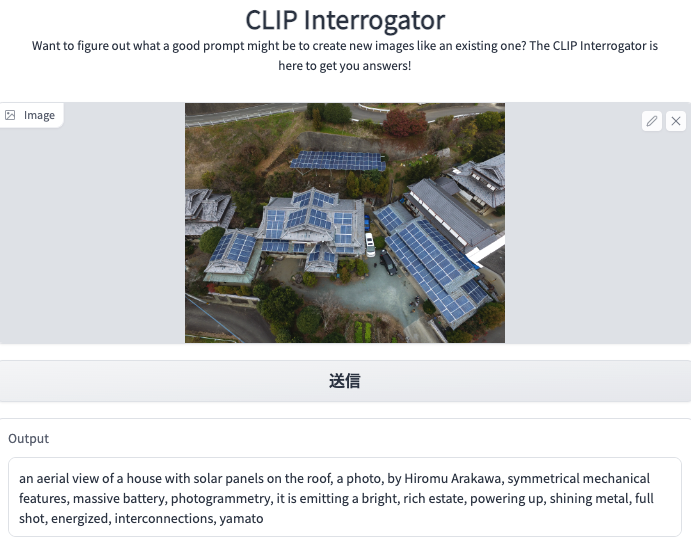
It is a pure old Japanese-style house but covered with many solar panels on the roof. Suppose the machine can recognize the solar panels. In this case, it is brilliant for two reasons: (1) Drone picture of a bird’s view, the recognization of the house needs to analyze the relationship between the house object and its environment. (2) The solar panels cover most of the roof area; Not a roof painting or light window, you might only recognize it “intelligently” with prior knowledge of solar panels.
Surprise us again. The machine recognizes the roof and solar panels correctly.
(Test 4)A geometry picture from web.
It is very abstract. All the above tests are the objects in real life, i.e., faces, house, solar panels, etc. Then we confirm the machine’s performance on pure abstract objects.
The result could be more satisfactory, finally. This test shows that the machine can perform excellently on some naturally detailed objects than abstract ones. Moreover, I’d like to learn more about its fundamental technique, which is Stable Diffusion.